Massive datasets meet their match
10-02-2025
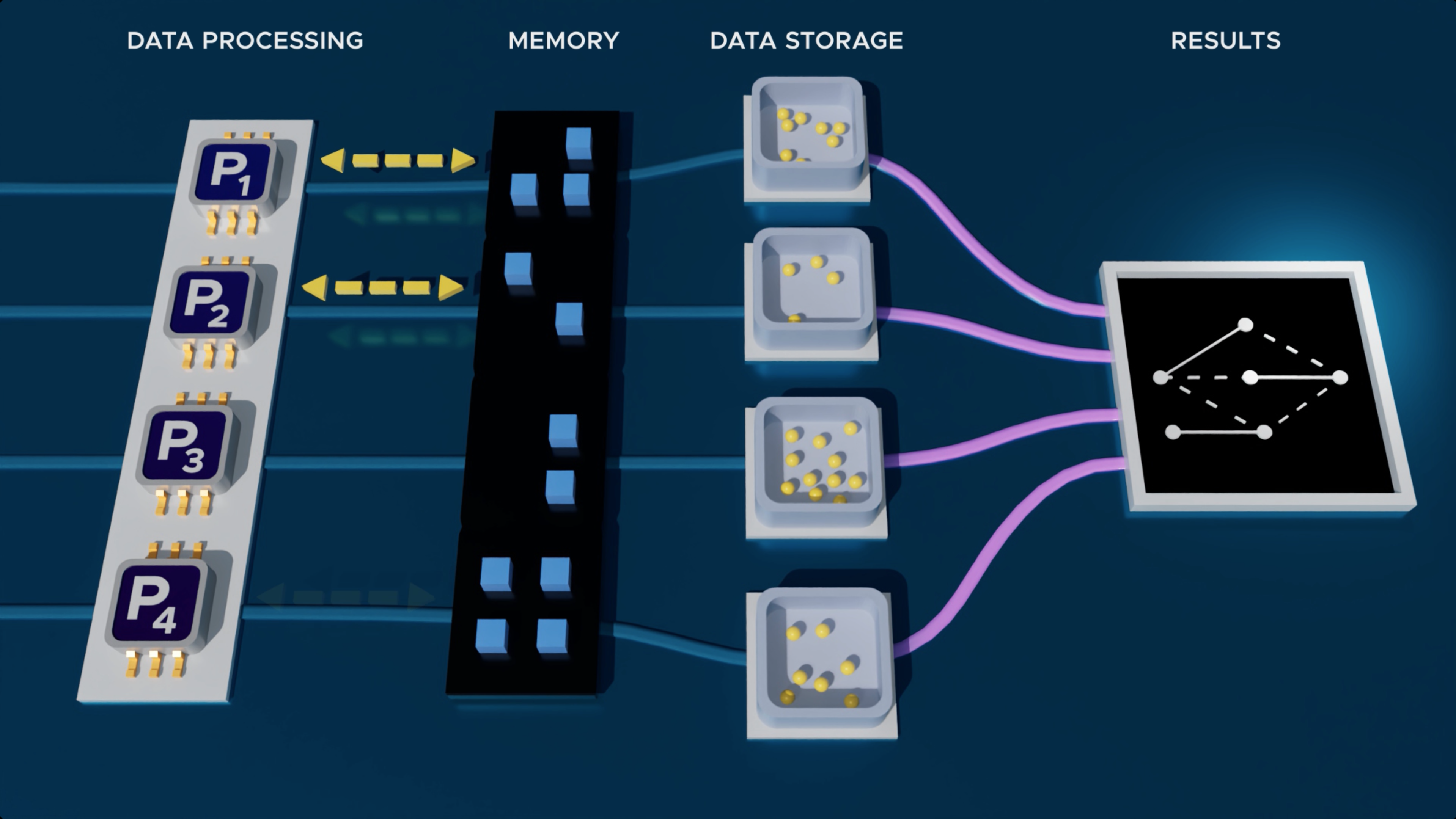
The poly-streaming approach allows for massive datasets to be analyzed while using small amounts of memory. (Illustration by Nathan Johnson | Pacific Northwest National Laboratory)
Award-winning poly-streaming approach processes massive datasets faster while using limited memory
Just as streaming services have replaced CDs and DVDs by letting people watch or listen without downloading all of the content first, data streaming lets scientists analyze raw data from tools like microscopes and drones without needing to save the entire dataset beforehand.
Recent research by Ahammed Ullah and Alex Pothen at Purdue University, and S. M. Ferdous at Pacific Northwest National Lab makes this analysis significantly faster, and in the process, they found a way to make extreme-scale data AI-ready. By combining streaming with parallel computing, Ullah, in collaboration with Ferdous and Pothen, developed an algorithm that speeds up data analysis by nearly two orders of magnitude.
Powering a poly-streaming model with parallel computing
For algorithm design and analysis, researchers use models of computation, which are agreed-upon rules for what operations an algorithm can perform and what resources it can use. Different models capture different settings. The classic RAM model does not impose a strict memory limit, but in a streaming model, memory is limited.
A streaming algorithm processes a large dataset sequentially, often in one or a few passes, while maintaining a compact summary that fits in its limited memory. These summaries are designed to recover a high-quality solution for the entire input.
“The poly-streaming model generalizes streaming to many processors and streams. Each processor maintains a small local summary of what it sees. Processors communicate as needed, which helps them choose summaries of good quality while limiting the number of passes. With suitably designed algorithms, the combined summaries suffice to obtain a high-quality solution,” Ullah explained.
Ullah formulated the poly-streaming model as part of his PhD thesis, advised by Pothen, and in collaboration with Ferdous. Within this framework, algorithms can jointly optimize time via parallel computing and space via data summarization. The researchers demonstrated its effectiveness using the maximum weight matching problem in graphs, a classical optimization problem with many applications.
The poly-streaming approach allows for massive datasets to be analyzed while using small amounts of memory. (Graphic by Nathan Johnson | Pacific Northwest National Laboratory)
Making large datasets manageable
“The size of data is getting larger and larger,” said Ferdous, a Staff Scientist and past Linus Pauling Postdoctoral Fellow at PNNL, whose PhD is from Purdue’s Computer Science department. “When the datasets get too large, we can’t easily store them on a computer. At the same time, we need to solve larger and larger problems involving these datasets.”
One solution has been to use supercomputers, such as the El Capitan exascale computer developed by the Department of Energy (DOE). However, some problems are too large for even the supercomputers to handle, and the large number of memory accesses increases the time needed to solve them. Streaming the datasets circumvents these memory storage issues, since only a small summary of the data is saved in the streaming model, and thus the memory needed to analyze the dataset is much smaller.
“While this doesn’t give an exact solution, we can prove that the approximations are accurate; they are a factor of two off the best solution, in the worst-case,” said Pothen, professor of computer science at Purdue University and Ullah’s PhD advisor.
Making extreme-scale data ready for AI
Optimization problems such as the maximum weight matching (MWM) problem have many applications. One such application is in the field of artificial intelligence (AI), where the data may need to be denoised and reduced in size before it can be analyzed. The MWM problem can play a crucial role in processing data for AI tasks by identifying significant subsets of the data. This preprocessing step makes the data more relevant, and leads to more accuracy in reasoning tasks.
Making large datasets “AI-ready” can be a challenge. Taking raw data and running it through an AI model without first denoising the data or reducing its size may lead to inaccurate results or make the computations infeasible.
“The poly-streaming model has the ability to process extreme-scale data,” said Ferdous. “Our model can act as the mediator between the raw data and the AI model by processing and making sense of the data before the AI model analyzes it further.”
Looking ahead, the research team sees their model as being especially applicable for processing the large amounts of data from DOE’s scientific user facilities and preparing it for AI analysis, bridging the gap between AI and instrumentation.
The theoretical contributions, practical performance, and the applicability of the poly-streaming model were recognized with the best paper prize at the recent European Symposium on Algorithms, which took place in Warsaw, Poland during September 15-17, 2025. This work was supported by the Advanced Scientific Computing Research program of the U.S. Department of Energy, and by PNNL’s Linus Pauling Distinguished Postdoctoral Fellowship
About the Department of Computer Science at Purdue University
Founded in 1962, the Department of Computer Science was created to be an innovative base of knowledge in the emerging field of computing as the first degree-awarding program in the United States. The department continues to advance the computer science industry through research. U.S. News & World Report ranks the department No. 8 in computer engineering and No. 16 overall in undergraduate and graduate computer science. Additionally, the program is ranked No. 6 in cybersecurity, No. 8 in software engineering, No. 13 in systems, No. 15 in programming languages and data analytics, and No. 18 in theory. Graduates of the program are able to solve complex and challenging problems in many fields. Our consistent success in an ever-changing landscape is reflected in the record undergraduate enrollment, increased faculty hiring, innovative research projects, and the creation of new academic programs. The increasing centrality of computer science in society, academic disciplines and new research activities — centered around foundations and applications of artificial intelligence and machine learning, such as natural language processing, human computer interaction, vision, and robotics, as well as systems and security — are the future focus of the department. Learn more at cs.purdue.edu.