A simple explanation of transformer embeddings + classroom activity
10/15/25 • 2-10min read
Here is a simple way to explain embedding models to a class (originally stated for collegiate-level classrooms). If unfamiliar with vectors, you can use the language of "sets" or "collections," but make sure to communicate that order matters. See the classroom activity at the bottom.
Let's say I've previously determined that the number of 'e's is the only important part of a word. I can tell you everything important about a sentence (like "Here it is") just using the number of 'e's in each word.
My embeddings model would then take any sentence and, for each word, give me back the number of 'e's in it (e.g. "Here it is" would give back 2, 0, 0).
Given a 3-word sentence, my output vector would be of length 3, and its 3D representation would lie at the point (x,y,z) where x, y, and z represent the number of 'e's in each word.
To me, any 3-word sentence with the same number of 'e's in each word as this sentence is identical ("There it was" would equal "Here it is", but "It is here" would not equal either).
(Notice that if you swap two of the words, I consider that a different sentence with a different meaning).
Embeddings are like this. Each "chunk" — whether that's a sentence, the next 2000 characters of my essay, or the next 4500 bytes of my image — is fed into my embeddings model which tells me all of what I previously determined was important. Notably, "everything I've considered important" should be a smaller size than the original input - our goal is to shrink the data (you could consider this a form of "summarizing").
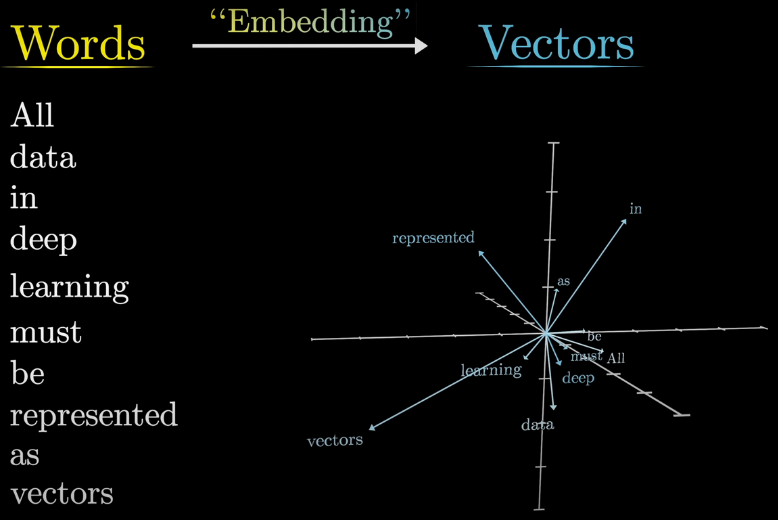
Consider the 3D Word Vectors image below. I could encode each word by the number of each letter it has — a vector of size 26. Instead, I have some embedding that tells me the 3 most important things about each word, and that is what is represented here.
Notice that in this model, the words "must" and "All" are considered similar, though this plot is likely random.
Figure 1: 3D Word Vectors. Source.
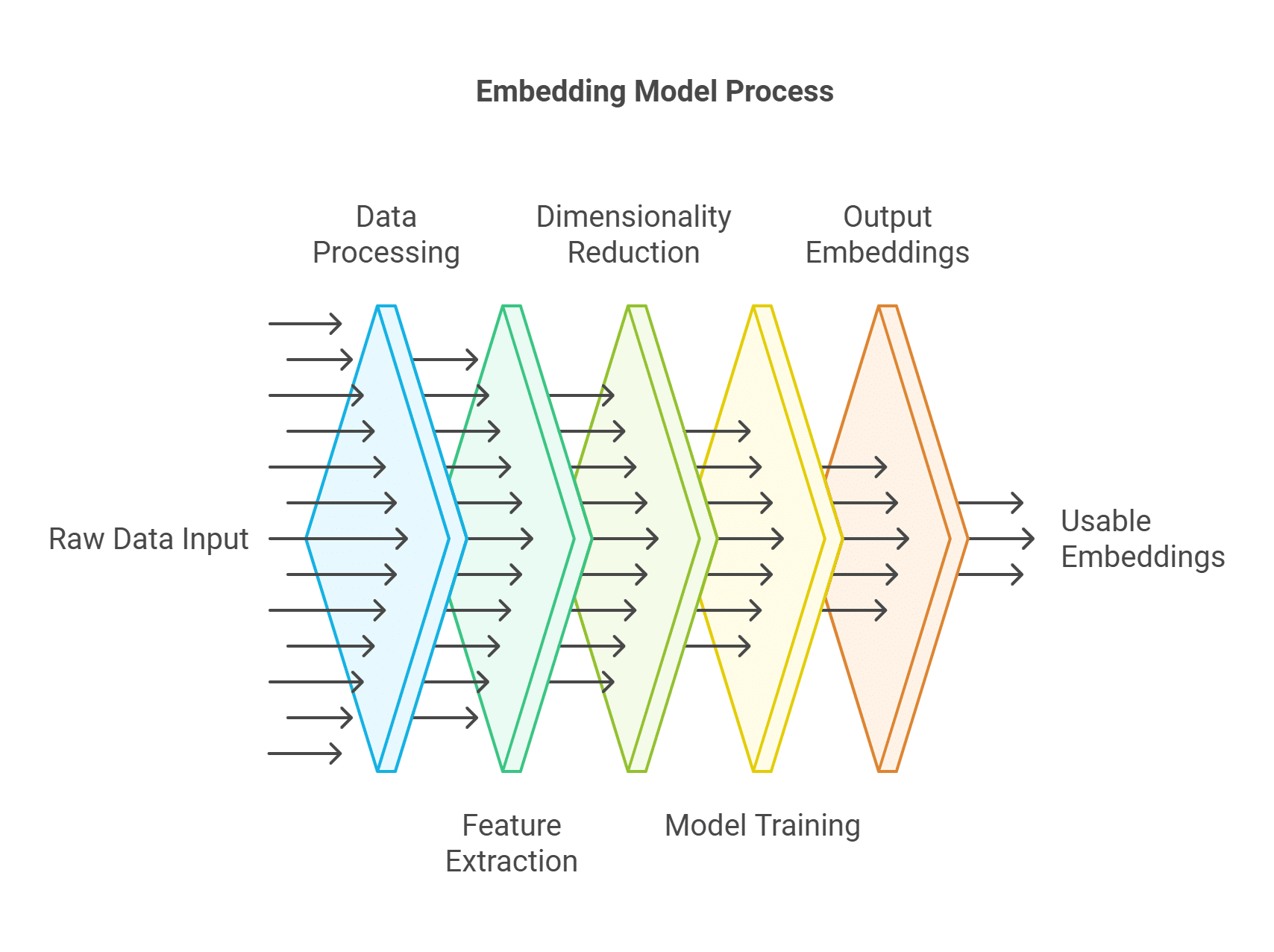
Embeddings models are trained like this, if you're curious:
Figure 2: embedding model training flowchart. Source.
In-Class Activity
Objective: Help students understand that an embedding is a compressed representation of words (or sentences) that keeps only the "important" information. Connect this with the idea of LLM pattern prediction.
This could be used in a greater lesson about transformers and broader discussion about whether LLMs "understand" things.
Split the class into small groups and give them a short word list, for example: {the, cat, chased, mouse, dog, barked, at, bird, lion, and, tiger, roared, bat, flew, over, fish, ran, from}.
Have groups brainstorm about the following question: If you could only save one piece of information about each word, what would you pick (e.g., number of letters, first letter, number of vowels)? Have them write it down for each word. For example:
apple → 5 letters
banana → 3 vowels
cherry → starts with C
Give each group a different secret sentence, for example: {"the cat chased the mouse", "the dog barked at the bird", "the lion and tiger roared", "the bat flew over the fish", "the mouse ran from the dog", "the cat ran from the dog", "the bat flew over the bird"}. Have them "encode" their sentence using the information ("features") they chose earlier.
Groups then trade sentences and try to reconstruct the original sentence.
Compare across groups. Who successfully reconstructed the sentence? Which words ended up looking the same? What differences got lost? What is the most ridiculous pair of words that seem similar under your encoding?
Debrief
Embeddings = compressed patterns, not full meaning.
LLMs use these patterns to predict the next word - they don't really "understand," they approximate by probability.
Humans do something similar when young: kids often lump categories by surface features (all four-legged animals as "dog") and only later refine meaning.
Modern models excel at producing cohesive, fluent thoughts from patterns, and while this isn't the same as human understanding, it raises the question of whether they might be moving along a path humans once took.
Prompt discussion: "If cat and dog are the same in your system, does that mean they really are the same? And if a model keeps refining its patterns the way children do, at what point (if ever) would we call that 'understanding'?" [See Broader Discussion below for a continuation of pattern vs thought questions.]
(Optional) Broader Discussion
To situate this into a broader discussion of thought, transformers, LLMs, and cognition, here are some ideas for discussion questions (untested in the classroom):
Pattern vs. Thought: Transformers excel at spotting patterns in massive datasets. To what extent can pattern recognition alone be considered a form of "thinking"? How does this compare with how humans learn from limited data and context?
When children refine categories over time, what helps them decide what really matters? Could a model ever have that kind of experience?
If a model becomes better at predicting because it captures richer patterns, is that just better pattern-spotting, or the start of genuine understanding?
At what point would you personally be willing to call what a model does 'understanding'? Is fluency enough, or do we require something more?
See ENE connection below for more explicit reasoning lines.
Understanding vs. Simulation: When an LLM gives a coherent response, do you think it "understands" the content, or is it merely simulating understanding? What criteria would you use to draw the line between genuine understanding and convincing imitation? At what age do humans achieve this criteria (babies certainly do not, for example)?
Context Windows and Memory: Transformers work with a fixed "context window," while humans have more fluid, long-term memory systems. How might these differences shape the kinds of tasks that LLMs are good at, versus the kinds of tasks where humans still hold an advantage?
Bias and Values: LLMs inherit biases from their training data. Humans also develop biases through experience and culture. How are these forms of bias similar or different? What responsibilities do engineers and educators have when deploying or teaching with LLMs?
Learning from Limited Examples: Humans often learn deeply from just a few examples (sometimes even one), whereas transformers typically require massive datasets. What does this say about efficiency in learning, and what could future AI systems borrow from human cognition to close this gap?
Connecting Pattern vs. Thought explicitly to Engineering Education (back to the original cause of this blog post):
When you first learned about forces, did you ever assume that heavier objects always fall faster? That's an over-generalization many students make. How is that similar to a model beginning with simplified patterns that don't capture the full truth? Other examples:
[ENGR] When you first learned about structures, did you assume "stronger material = better design," without considering tradeoffs like weight, cost, safety factors, flexibility, and context of use?
[CS] When you first learned recursion, did you ever assume the computer would ‘just keep going’ until it hit the right answer, instead of realizing you need a base case? Beginners often expect the pattern to resolve itself, but without structure, it never ends.
[MA] When learning algebra, did you ever assume that √(a + b) = √a + √b? If feels intuitive at first, but it's wrong.
My friends in ENE will recognize in each of these the idea of Difficult Concepts or Misconceptions that are used when designing a course. (See Perkins' ideas about reasons for difficulty on pages 89-105 of Making Learning Whole.)
As you advanced, what helped you refine what really mattered in problem-solving - was it practice, feedback, or deeper context? Could models ever gain that same kind of refinement?
At what point do we say a student doesn't just memorize formulas but truly understands engineering ideas? Would we ever apply the same standard to a model?