Kihong Park
Associate Professor | Department of Computer Science | Purdue University
Multiple time scale traffic control and Internet traffic
What it's about
Perhaps the most significant advance in network research in the 1990s was
the discovery of self-similar burstiness in network traffic
by Leland et al. in the
seminal paper "On the self-similar nature of
Ethernet traffic" (SIGCOMM '93).
Although Leland and Wilson had presented measurement results in earlier
work, it
was in the '93 SIGCOMM paper that a meaningful statistical framework
was put forth that succinctly captured burstiness in Ethernet LAN traffic
across a wide range of time scales.
The broader impact of the discovery has been two-fold: first, establishing a
much needed anchor in network research for measurement-oriented work
whose fruits are
visible today in a variety of network measurement studies, not confined
to traffic (e.g., topology, DoS, worms, faults,
and mobility); second, triggering
advances in performance evaluation under long-range
dependent input through interdisciplinary efforts by
researchers in CS, EE, OR, mathematics, and physics.
Queuing theory received a significant boost
by being provided with both a practically
relevant and technically challenging research problem.
The impact of Leland et al.'s paper in providing
balance to network research between modeling and measurement
cannot be overemphasized. The balance is still shaky,
not as established as in physics where the
interplay between theoretical and experimental physics has been
crucial to yielding "good" science.
We may consider three types of questions regarding self-similar network traffic: What causes self-similar burstiness? What is its impact? What can be done about it? The first question concerning "why" is fundamental to any scientific endeavor. The second question addresses the performance implication of the empirical phenomenon. The phenomenon may be an interesting intellectual curiosity, but if the performance effect is marginal then its practical relevance is limited. The third question addresses the problem of control. If self-similar burstiness is "bad," do we take it lying down or can something be done about it ("make lemonade out of lemon")? My efforts have focused on the first and third questions.
Contribution
What causes self-similar traffic?
I was at the '93 SIGCOMM conference presenting my first
networking paper, "Warp control: a dynamically stable congestion protocol
and its analysis" as a Ph.D. student, which exposed me to Leland et al.'s
results early on. I had worked as a RA on fractal image compression with
Karel Culik II during my Master's studies,
so was familiar with some aspects
of its mathematics
(dynamical systems
over measure spaces used in Barnsley's IFS).
My first suspicion was that multi-layering in the protocol stack (i.e.,
TCP, IP, CSMA/CD) might be injecting recursive spacing into packet
transmissions (somewhat like a Cantor set)
resulting in self-similarity. Discussion with others
at the conference, and further reflection, made me realize that the
mechanisms in the protocol stack
are unlikely to be the cause given the large time
scale at which traffic burstiness was preserved. I left the conference
with a small curiosity stewing on the backburner.
Fast forward to 1995 when Paxson and Floyd's '94 SIGCOMM paper
"Wide-area traffic: The failure of Poisson modeling" showed that ftp
data sessions tend to have heavy tails (even though connection arrivals
were approximately Poisson); Willinger et al.'s '95 SIGCOMM paper
showed that on-periods in Ethernet LAN traffic possessed heavy tails
which, together with Paxson and Floyd's results, provided strong
evidence that heavy-tailed flow durations were responsible for
generating self-similarity and long-range dependence. In 1995, Carlos
Cunha, a fellow grad student at BU, was collecting WWW client
request traces that showed that web requests tended
to be heavy-tailed ("Characteristics of WWW client-based traces"
by C. Cunha, A. Bestavros and M. Crovella, Tech Report,
BU-CS-95-010, 1995).
It became clear that self-similar network traffic could be an induced
phenomenon whose roots may be traced to heavy-tailed file size
distributions on the Internet, a structural property of a
distributed system.
To establish the causal chain —
file sizes are heavy-tailed and exchange of heavy-tailed files
mediated by network protocols manifests in self-similar traffic
— we needed to demonstrate that file systems are typically heavy-tailed
and network protocols do not disrupt translation of application
layer heavy-tailedness to network layer long-range dependence.
In the '96 ICNP paper, "On the relationship between file sizes, transport
protocols, and self-similar network traffic"
(with G. Kim and M. Crovella), we showed that UNIX file systems research
carried out in the 1980s showed results consistent with
heavy-tailedness, although they were not presented through this
technical prism. Since Leland et al.'s '93 SIGCOMM paper used
Bellcore traffic measurement from 1989-1992 before
the advent of WWW, revisiting the file systems research results
from the 1980s provided independent evidence that file systems
tended to be heavy-tailed.
The '96 ICNP paper also tackled the influence of the protocol stack
question. In a nutshell, we showed that TCP, due to it reliability
and congestion control mechanisms, preserves heavy-tailedness
in file sizes that is translated into heavy-tailed flow duration
that then manifests as self-similar and long-range dependent
network traffic. UDP-mediated file transfer traffic under
aggressive congestion control can diminish the transfer effect resulting in
significantly reduced long-range dependence as measured by the
Hurst parameter H. This "clipping effect" can be
understood as a weakening of the signal strength nascent in
the file size tail stemming from non-conserved data transfer.
Fig. 1(a) shows the Hurst parameter estimates (V-T, R/S,
periodogram) of aggregated TCP file traffic at a shared router
link for tail index alpha = 1.05, 1.35,
1.65, and 1.95. We find an approximately linear relationship
between H and alpha: the more heavy-tailed the file
size distribution, the more long-range dependent the resultant
multiplexed TCP file traffic.
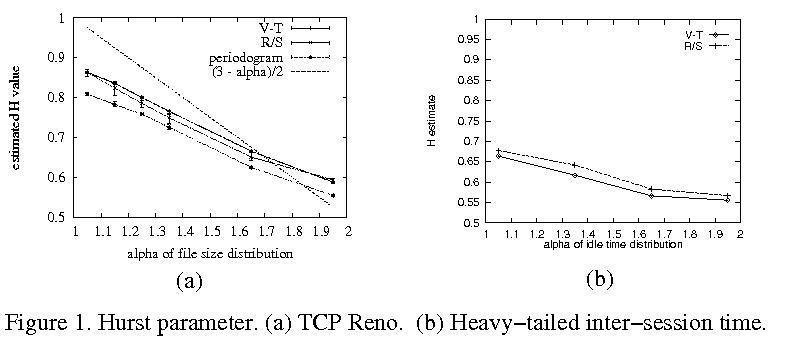
In Fig. 1(a) we also observe that the slope of the
alpha-H line is less than (3-alpha)/2, the value
predicted by on-off traffic with heavy-tailed on-periods
and exponential off-periods. We ascribed this to
the congestion control actions of TCP that inject
irregularities into the transmission ("saw tooth
pattern") reducing some of the signal strength when
alpha is close to 1 (i.e., very heavy-tailed).
When alpha is close to 2.0 (almost
light-tailed), then the shallower slope leads to a higher
H value than the predicted 0.5.
Even when file sizes are not very
heavy-tailed, TCP congestion control, in particular,
exponential backoff, can inject prolonged pauses in the
transmission which is a form of correlation (mathematically
on-off traffic with exponential on-periods but
heavy-tailed off-periods is also long-range dependent).
This may be gleaned from Fig. 1(b) which shows
estimated Hurst parameter as a function of tail index alpha
when file sizes are exponential but inter-session idle
time (i.e., off-period) is heavy-tailed. Depending on the
tail index of the inter-session idle time, the resultant
H deviates significantly from 0.5.
The flip side of "TCP can generate nontrivial correlation
through persistent pause injection"
is that transmission pauses stemming from
exponential backoff can exert a sender-side "backlog
effect" conducive to bursty transmission.
That is, in operating systems such as
UNIX and Windows, the write() system call
copying data from user space to kernel space (TCP buffer) is
a blocking call that returns
when copying to kernel space has completed. Since
TCP writes triggered by an application layer process
may occur asynchronously to TCP congestion control actions
in the protocol stack,
during exponential backoff the sender-side TCP buffer may accumulate.
The net effect is that backlog build-up
translates to bigger workload, similar to transmission
of larger files.
This source of traffic correlation, although
nontrivial, is tertiary to heavy-tailed file sizes with
respect magnitude of impact due to limited buffer sizes.
This linkage between traffic and congestion control has
captured the imagination of some researchers (Veres and Boda's
INFOCOM '00 paper "The chaotic nature of TCP congestion
control" espouses the theme that nonlinear TCP dynamics
can generate correlation-at-a-distance).
What can be done about it?
The "bad news" about self-similar Internet traffic is that strong
correlation-at-a-distance can result in increased queuing delay
and packet loss at routers, even when buffers are large.
Very long packet trains that were exponentially rare events
under Markovian input now become only polynomially rare.
From a resource provisioning perspective, self-similar
burstiness implies persistent periods of underutilization
and overutilization that make efficient QoS provisioning
inherently difficult.
The "good news" is that the same correlation-at-a-distance that
affects adverse collusion yields predictability
at large time scales that may be harnessed by traffic control
for improving performance.
The main idea behind multiple time scale traffic control is that
correlation at large time scales may be harnessed to modulate control
actions at smaller time scales to improve performance.
Under construction.
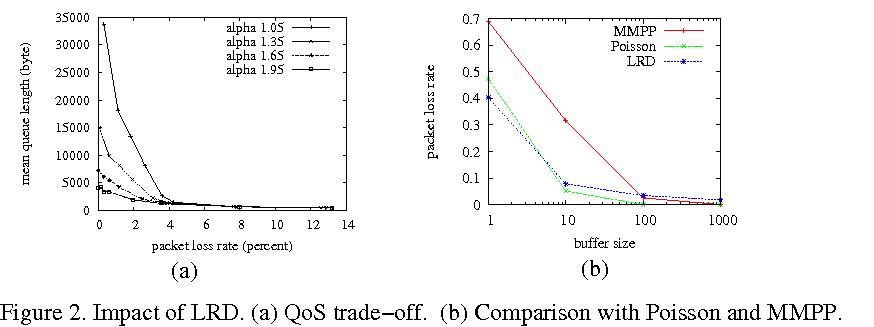
Fig. 2(a) shows the trade-off relation between packet loss rate
and delay under aggregated TCP file traffic for varying
file size distribution tail index values 1.05, 1.35, 1.65,
and 1.95. The data points are
obtained for fixed bandwidth but
varying bottleneck link buffer sizes
(details can be found in the '97 SPIE paper "On the effect of
traffic self-similarity on network performance"
with Kim and Crovella).
For example, when alpha decreases from 1.95 to 1.05, to maintain
a packet loss rate of 2%, a significantly higher delay —
more than 5-fold increase — needs to be incurred.
As a resource provisioning strategy, bandwidth dimensioning is
more effective than buffering.
Following queuing analysis by Norros (Queueing Systems '94),
Likhanov et al. (INFOCOM '95), and others, who established
subexponential queue length distributions under LRD input,
there ensued a heated
debate as to whether long-range dependent traffic, compared to
short-range dependent — in particular, Markovian — traffic,
indeed leads to amplified packet loss in finitary systems
(rigorous queuing analysis with LRD input employs asymptotic
techniques).
The debate was not all that informative, perhaps resembling
the social spectacles that occur in the sciences from time to time,
the Keynesian-monetarist debate in macroeconomics being a
canonical example of degenerate opining. The answer to the
LRD vs. SRD debate, not surprisingly, is not a simple "yes or no"
but "it depends."
Fig. 2(b) compares packet loss rate when a queue is fed with
LRD, Poisson, and MMPP input for buffer capacity 4 orders
of magnitude apart. The 2-state MMPP has transition rates that
make it extremely bursty. The average data rates of LRD,
Poisson, and MMPP traffic are kept the same. When buffer
size is 1, we find that LRD incurs the least packet drop, followed
by Poisson. MMPP is well-ahead of both. At buffer size 10, there
is an inversion between LRD and Poisson, but MMPP remains ahead
of both by a large margin. At buffer size 100, LRD (barely) overtakes
MMPP, incurring the highest packet loss rate. At buffer size 1000,
the relative gap between LRD and MMPP packet loss has amplified
significantly. Thus the answer is conditional: at smaller buffer
sizes, short-range correlation in Markovian traffic may dominate
buffer overflow dynamics. At larger buffer sizes,
overflowing the buffer requires very long packet trains that are
much more likely under LRD input than SRD input. What constitutes "small"
or "large" is a quantitative question that depends on many
parameters.
Under construction.
AcknowledgmentsUnder construction.
References
 This page is under construction.
This page is under construction.