Note: You need to have a campus IP address (e.g., using VPN)
or authenticate using Boilerkey to get some parts of the assignment.
Please turn in a PDF through Gradescope.
You'll need to access Gradescope through Brightspace the first time (to register you for the course in Gradescope.)
Gradescope is pretty self-explanatory,
ITaP provides these instructions.
Make sure that you mark the start/end of each question in Gradescope. Assignments will be graded based on what you mark as the start/end of each question.
Please typeset your answers (LaTex/Word/OpenOffice/etc.)
1: Association Rules
Suppose Apriori is applied to the dataset below with minimum support 30\%:
TransID
items
1
{a,b,d,e}
2
{b,c,d}
3
{a,b,d,e}
4
{a,c,d,e}
5
{b,c,d,e}
6
{b,d,e}
7
{c,d}
8
{a,b,c}
9
{a,d,e}
10
{b,d}
Draw an itemset lattice representing the data above (with ∅ at the bottom). Label each node F if it is a frequent itemset, I if it is a candidate that is found to be not frequent, and N if it would not to be considered as a candidate.
What is the percentage of all possible itemsets that are frequent?
What is the pruning ratio (the percent of possible itemsets that are not tested to see if they are frequent)?
What fraction of itemsets that are considered (tested to see if they are frequent) are found to be not frequent? Is considering these likely to cause significant performance issues? Explain.
Give the association rules that hold with at least 30% support and 50% confidence.
2: Sequential Pattern Mining
You are given a transaction record of five different customers in a supermarket.
Date
Customer ID
Items bought
March 12
2
Apple, Beer
March 15
5
Wine
March 17
2
Cheese
March 23
1
Cheese, Wine
March 23
2
Chips, Scissors, Salami
March 28
1
Wine
March 28
3
Cheese, Eggs, Salami
March 28
4
Cheese
March 31
4
Chips, Salami
April 3
4
Wine
Rewrite the given data to a sequence database where the first column is customers and the second column is the item sequences
Identify all length-2, length-3, length-4 sequences starting with Cheese
Compute the support and the confidence values of the three sequences:
{Cheese} → {Salami}
{Cheese} → {Wine}
{Cheese} → {Salami, Wine}
3: Causal Reasoning
Association rules with high support and confidence suggest a meaningful pattern - if we have A → B with high confidence and support, it suggests that A causes B. But this can be misleading.
Give an example of an association rule with high confidence and support, where the causal relationship doesn't hold. Hint: use the idea of counterfactuals in causal reasoning.
Could this still potentially be a problem if your association rule had high lift?
4: Bayesian Networks
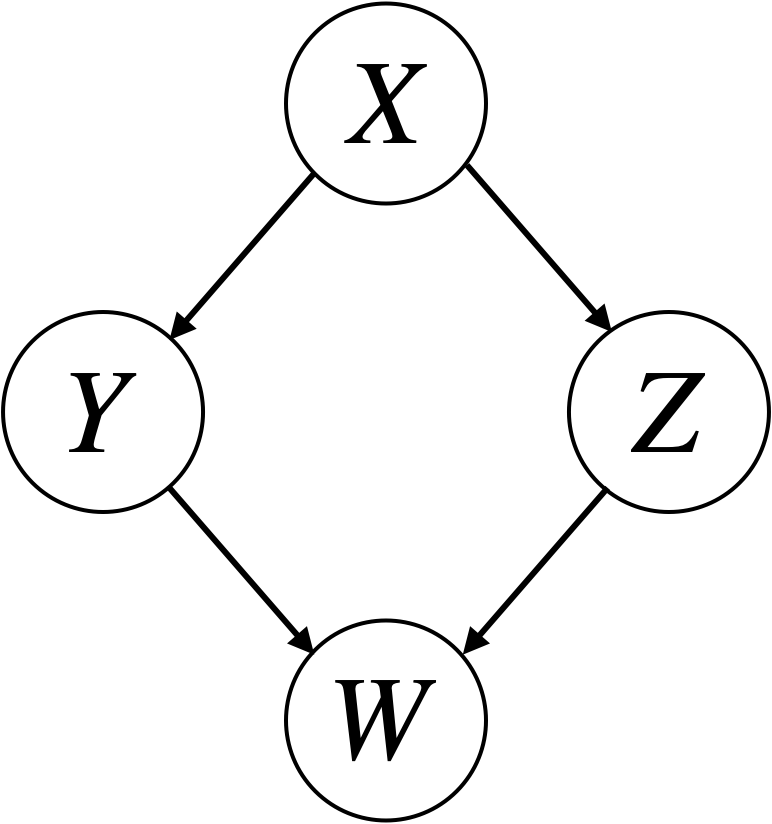
You are given a Bayesian Network with four random variable nodes, X, Y, Z, and W.
Suppose P(X) = 0.6, P(Y|X) = 0.3, P(Y|~X) = 0.4, P(Z|X) = 0.8, P(Z|~X) = 0.1, P(W|Y, Z) = 0.4, P(W|Y, ~Z) = 0.2, P(W|~Y, Z) = 0.3, P(W|~Y, ~Z) = 0.1. If the observed X value is false, what is the probability of W being true?
Given the same probabilities, are Y and Z independent or dependent? Show it mathematically. If Y and Z are dependent, is it possible to modify the probability values to make them independent? If so, show that they are now independent.
5: Anomaly Detection
Given the following figure:
Would p1 and/or p2 likely be considered an outlier under each of the following approaches?
Local Outlier Factor (LOF): Determines if a point is in a less dense region than its neighbors. Assume k=5.
LOFk(A):=ΣB ∈ Nk(A)lrdk(B)/lrdk(A)/|Nk(A)|
= ΣB ∈ Nk(A)lrdk(B)/|Nk(A)| · lrdk(A), where
the local reachability density of an object A is defined by
lrdk(A):=1/(ΣB ∈ Nk(A)reachability-distancek(A, B)/|Nk(A)|)
K-Means Clustering, with k=2 - assume any cluster with fewer than three points is outliers.
K-Means Clustering as above, with k=3 - assume any cluster with fewer than three points is outliers.
DBScan with appropriate parameter settings so that C1 and C2 are both considered to be clusters - again, assume any cluster with fewer than three points is outliers.
Explain the reasoning behind your answers.
6: Data Mining Process
It has been shown that data mining can results in outcomes that are gender, racial, and ethnically biased. While the CRISP-DM process does not explicitly address such discrimination, there are ways to address this as part of the process.
Identify at least three tasks in the CRISP-DM process where action could be taken to address fairness/bias issues. For each, describe an activity or activities to be undertaken, and the outputs. Your description should be at the level of detail of the entries in the CRISP-DM - e.g, one or two sentences for an activity, a sentence for an output.
Which of these items do you consider the most critical to achieving fairness? Explain why.
For one of the tasks, give a hypothetical example of the output you would include in the report. If appropriate, you can base this on your final project - although you can choose another scenario, if you wish.