Assignment 1: Probability, Data Mining Process
Due 11:59pmEDT Friday, 21 Januarly 2022
Note: You will need to have a campus IP address (e.g., using VPN)
or authenticate using Boilerkey to see the full assignment.
Please turn in a PDF through Gradescope.
You'll need to access Gradescope through Brightspace the first time (to register you for the course in Gradescope.)
Gradescope is pretty self-explanatory,
ITaP provides these instructions.
Make sure that you mark the start/end of each question in Gradescope. Assignments will be graded based on what you mark as the start/end of each question.
Please typeset your answers (LaTex/Word/OpenOffice/etc.)
1: Vizualizations and Probability Measures
For each of the following graphs and statements, note if the statement made is true, false, or cannot be determined based on the graph. Briefly explain your answer.
-

-
Mean value of Facebook in 2011 is μ = $79.58B
-
The value of Facebook more than doubled in the first three months of 2011.
-
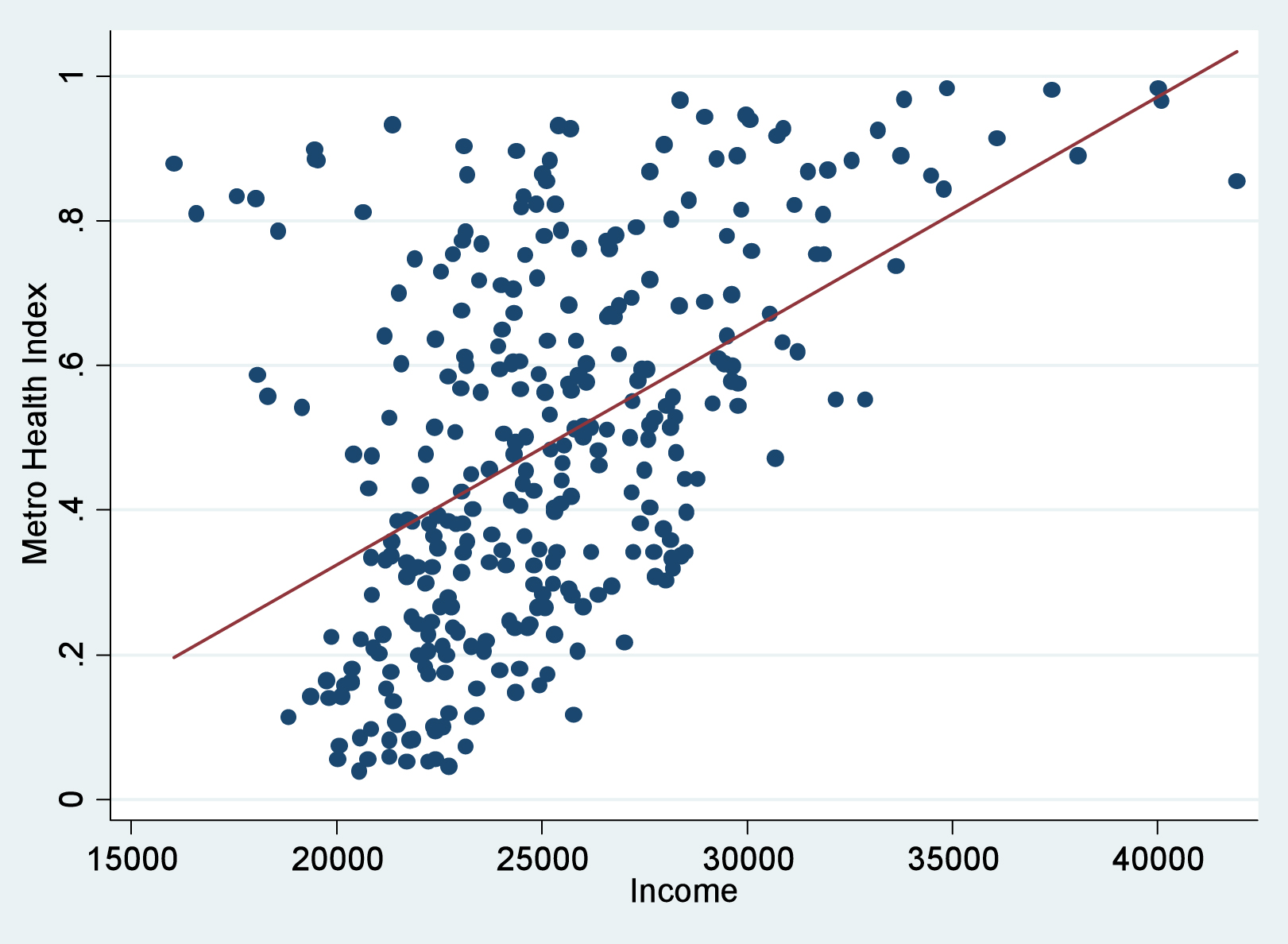
-
Income and the Metro Health Index are correlated.
-
Income and the Metro Health Index are positively correlated.
-
Income and the Metro Health Index have a linear relationship.
-
Increasing income leads to better health.
2: Below is the graph of a probability mass function of tossing an unfair dice.

-
Derive a probability mass function from the graph.
-
Consider you toss this dice twice. What is the probability that the sum of the numbers rolled is greater than 8, given the first number rolled is 5?
- What is the expectation and the variance of the numbers rolled?
- When we roll this dice twice, what is the expectation of the product of the numbers rolled?
- When we roll this dice 2000 times, what is the expectation and the variance of the sum of the numbers rolled?
3: Programming exercise
Given the yelp dataset (use the provided yelp.csv), answer the following questions. Keep in mind, these questions need visualization to picture the data. R, SAS, Python any platform is acceptable. However, use of R/SAS is encouraged. Include screenshots in your pdf for each part. Also include code snippets. If using R, use of R-Markdown file is preferred. Just include the code in the PDF (inline or as an appendix, whichever you feel reads best.)
Note: The dataset has blanks, NAs. Ignore them in your analysis.
- For the column state, draw the barplot. What do you notice?
- Draw the histogram (default params) for variable latitude.
- Provide the 5 point summary (min, 1st Quartile, Median/ 2nd Quartile, 3rd Quartile, Max, Mean) summary of the variable latitude. Calculate the variance, standard deviation, and skewness. Do these values align with observation on the histogram?
- Now plot the Histogram of latitude with three bins. Are the shapes capturing the same distribution?
- Plot the Density plot (default params) of latitude
- Plot the scatterplot of reviewcount and checkin. Describe what you see.
- Draw the Boxplots for the following variable combinations, with the categorical variable on the horizontal axis. Describe what you see and give a plausible explanation for what is shown.
- Stars and alcohol
- Stars and state
- Pricerange and attire
- Checkins and delivery
- Originally, stars has values 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, and 5.
We define a High-end restaurant as 3.5 stars and above. Make a new boolean variable
isHigh-End
and answer the following questions:
- Plot the Barplot of isHigh-End with Pricerange. Comment on what you see.
- Define Success Rate as:
Number of high-end restaurants for that price range value / total number of restaurants for that price range value
Plot a scatterplot of success rate and price range. What do you see?
4: Use of data mining
Find an example news article from the last year (other than the examples given here) that either
talks about data mining,
demonstrates a use of data mining,
or required some sort of data mining to develop the article.
- Briefly describe what either the story says, or you hypothesize, must have been done for each step of the data mining process (selection, preprocessing, ...)
- Pick one statistic that is given either numerically or as a visualization. If numeric, describe or draw a possible visualization that would capture that statistic. If a visualization, describe in more formal mathematical terms something that is shown in the visualization.
We're expecting discussions of half a page to a page total.
