Assignment 4: Machine Learning in Web Information Management
Due 11:59pmEDT Friday, 23 October, 2020
Please turn in a PDF through Gradescope.
Please typeset your answers.
1. Web Crawling: Duplicate Elimination
For this question, you will use four-term shingles and Jaccard coefficient to compare documents.
- A. Compute the Jaccard Coefficient for the following pair of documents. Please show your work.
- D1:
- i love cats more than dogs
- D2:
- i love cats less than dogs
- B. Now, compute the Jaccard Coefficient for these next two documents. Please show your work.
- D3:
- i really really do love dogs
- D4:
- i really really do love cats
- What do you notice about the Jaccard Coefficient scores, in relation to how "similar" each pair of documents is?
You should see a a bit of a flaw in this approach - describe what it is and how you mjght deal with it.
2. PageRank
In this graph, A, B, C, and D are four webpages linking to each other.
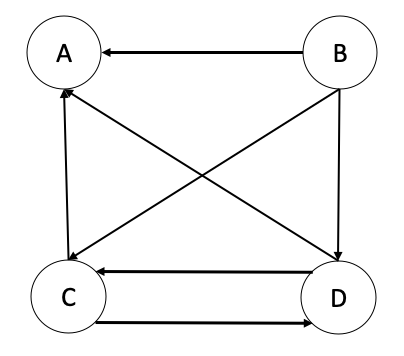
Assume the probability of following each link is equal.
- Show the Matrix Notation of these webpages. Order the element in the sequence: A, B, C, D.
- Run the HITS algorithm on this graph, simulating the algorithm for three iterations. Show the Authority score and Hubness score for each page in each iteration.
- Assume the damping factor (1-ε in the formula on slide 40) is 0.85, run the Pagerank algorithm (random walk model) on this graph. Simulate the algorithm for three iteration. Show the pagerank score (normalized) for each page in each iteration. Note: If you did this using the formula on slide 34, with α as the damping factor, that is okay as well. You should be able to easily figure what htis will converge to.
- Please compare HITS and Pagerank. Briefly, elaborate the pros and cons of HITS and Pagerank.
- How close do you think each is converging, and do you think the values you have are close to the values they would converge to?
3. Query Expansion
-
Suppose the users of your informatino retrieval system feel that that none of returned rsults meet their information needs. Explain the problem in terms of precision and recall. Include an example describing your explanation(s).
-
Given your example, how would you expect query expansion to affect:
4. Relevance Feedback
Given a similar case to your search engine in Question 3.
-
Explain why relevance feedback might be difficult to use. (Please list two reasons, each of them in one sentence is enough.)
-
Suppose that a user's initial query is inverse document frequency is importance of a term in a corpus. The user examines two documents, d1 and d2.
- d1 (relevant):
- inverse document frequency importance in corpus
- d2 (irrelevant):
- document essential corpus
Assume that we are using direct term frequency (with no scaling and no document frequency). There is no need to length-normalize vectors. Using Rocchio relevance
feedback, what would the revised query vector be after relevance feedback? Assume α = 0.75, β = 0.25.
(Note: If using the version given in the books, use α = 1, β = 0.75, γ = 0.25; the books list a slightly different notation that introduces an additional parameter. If you already did it using the version in the slides with α = 1, β = 0.75, and ignoring γ, then that is fine. Although for the theory to work out right, the parameters for relevant and non-relevant documents should sum to 1.)
5. Text Categorization
For this question, you will be presented with training data documents, with category labels "P"etLover or "M"otorhead. Perform KNN classification on the
new document DN with n = 2, using TF-IDF vectorization of the documents. Please show your work.
| DocID | Text | Category |
|---|
| D1: | i love cats | PetLover |
| D2: | i love dogs | PetLover |
| D4: | i love cars | Motorhead |
| D5: | i hate cars | PetLover |
| D6: | i hate cats | Motorhead |
New document to categorize (DN):
- DN:
- i love cats dogs
