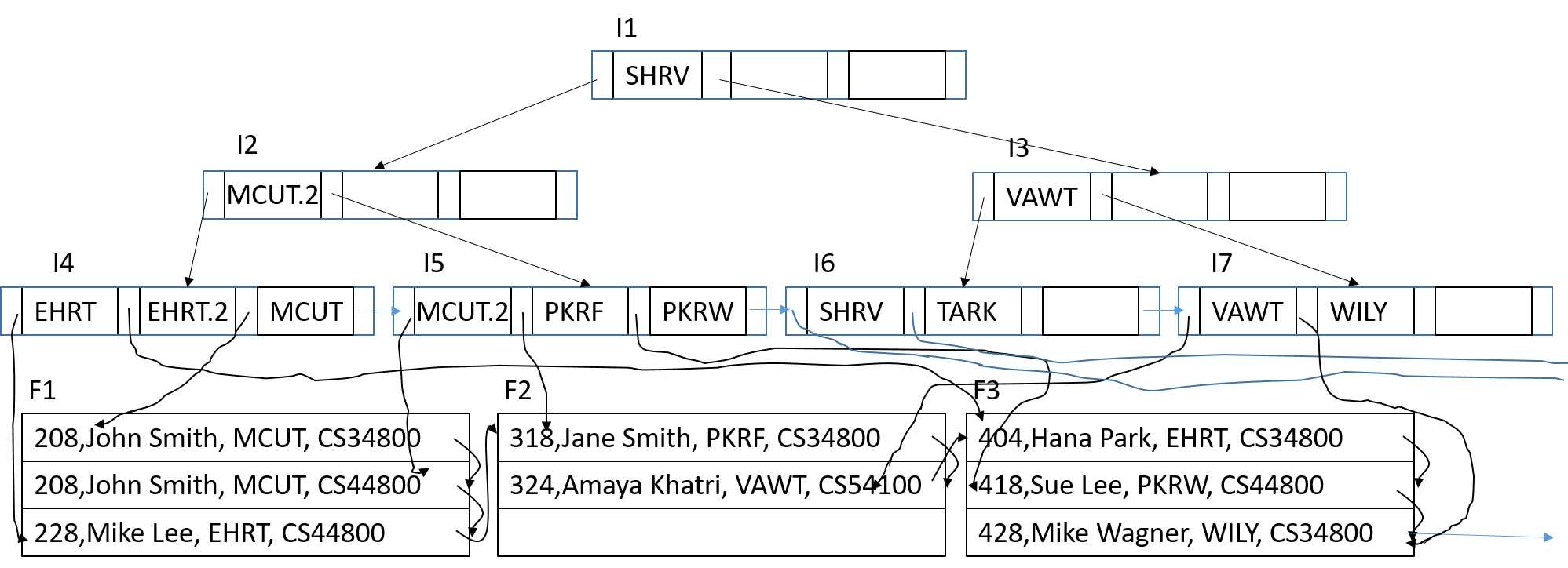
(Note that some of the data blocks are "off the page", but won't be needed for what you are doing.)
Please turn in a PDF through Gradescope. Make sure that you mark the start/end of each question in Gradescope. Assignments will be graded based on what you mark as the start/end of each question. Please typeset your answers where feasible, handwritten answers will be acceptable for drawings (e.g., trees).
Given the following B+ Tree, an index by residence hall, and database file (consisting of students, their classes, and their residence hall):
(Note that some of the data blocks are "off the page", but won't be needed for what you are doing.)
Note that search keys are not unique, which is a little difficult for B+ trees. One solution (discussed in Section 14.3.5 in the book) is to make each search key unique by appending a value (e.g., the primary key of the record, or a counter as shown here). All searches then become range searches (e.g., search for EHRT by looking for everything between EHRT and EHRT.999999).
PKRF: What blocks are read?
DELETE FROM students WHERE name = 'John Smith';
INSERT INTO students VALUES(314,'Jane Doe','CS44800','DUHM');
Repeat Question 1, but for the hash index below:
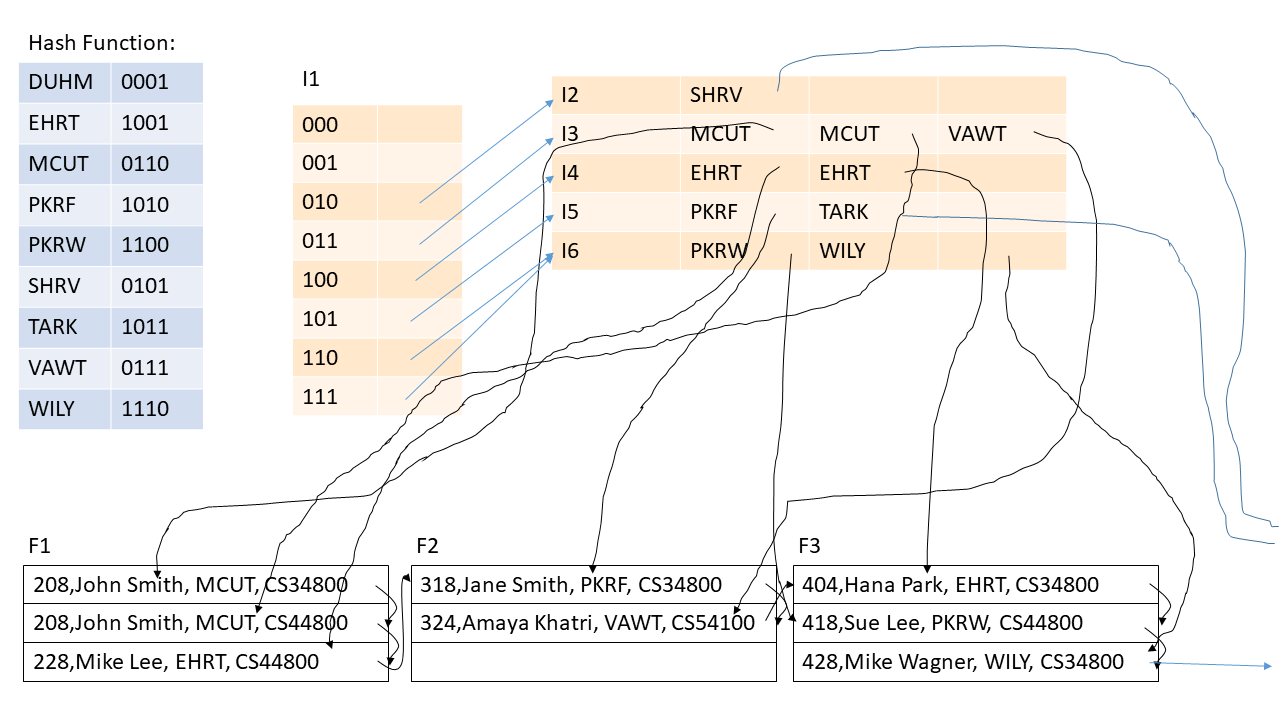
Is the relation in questions 1 and 2 a good design? Briefly explain why or why not.
Create a B+ tree from the following sequence of key insertions and deletions. Assume a fan-out of 3. Show the final tree. Note that there are many programs online that will do this for you. Using one of these won't really help you understand what is going on (and will be poor preparation for an exam.) Furthermore, some have bugs and won't give you the correct result.
Note that the search key is not a key, it may occur multiple times. Deleting (as with "delete 18" and "delete 4") should delete ALL occurrences, as it does with SQL.
Repeat question 4, but for extensible hashing. Assume a bucket size of 4.
Consider the following relation Employee (id: integer, name: String, salary: integer) where we have a hash index on id and a B+ tree index on salary. Now, consider the following three queries:
Select name
From Employee
Where salary >= 5000
Select name
From Employee
Where id = 10
Select name
From Employee
Where id = 10 AND salary >= 5000
For each of the above queries, decide which index/indexes you will use and explain why. Would any of these possible choices run into blocking operations that might impact pipelined evaluation, and if so, what would the potential impact be?
Let us consider a relation R (s, t, u) containing 1 billion (10^9) records. Each page of the relation holds 10 records. R is organized as a heap file with unclustered indexes and the records in R are randomly ordered. Assume that atribute s is a candidate key for R, with value lying in range 0 to 999,999,999. Now, for each of the following queries, name the approach that would most likely require the fewest I/Os for processing the query. Justify your answer by approximately calculating the cost (in terms of disk accesses) for each approach to answer each query.
The approaches to consider are as follows:
The queries are:
You'll need to start by estimating the size of the indexes. Assume you can fit 30 key/pointer pairs in a disk block (either a B+ tree index block, or a hash index block.) Additionally, assume that after accesing the data entry it takes one more disk access to get the actual record.