A Tutorial on Learned
Multidimensional Indexes*~
Abdullah Al Mamun
(Ph.D. Student)
Hao Wu (Undergraduate
Student)
Walid G. Aref
Department of
Computer Science
Purdue University
West Lafayette,
Indiana 47907, U.S.A.
*We acknowledge the support of the
National Science Foundation under Grant Numbers III-1815796 and IIS-1910216.
~This page is based on a tutorial
given at the 2020 ACM SIGSPATIAL Conference:
Abdullah
Al-Mamun, Hao Wu, Walid G. Aref: A Tutorial
on Learned Multi-dimensional Indexes. ACM SIGSPATIAL Conference, pp.
1-4, Nov. 2020. (pdf
of the tutorial proposal).
ABSTRACT
Recently, Machine Learning (ML,
for short) has been successfully applied to database indexing. Initial
experimentation on Learned Indexes has demonstrated better search performance
and lower space requirements than their traditional database counter parts.
Numerous attempts have been explored to extend learned indexes to the
multi-dimensional space. This makes learned indexes potentially suitable for
spatial databases. The goal of this tutorial is to provide up-to-date coverage
of learned indexes both in the single and multidimensional spaces. The tutorial
covers over 25 learned indexes. The tutorial navigates through the space of
learned indexes through a taxonomy that helps classify the covered learned
indexes both in the single and multi-dimensional spaces.
OUTLINE
OF THE TAXONOMY
An updated version of the
taxonomy is given below.
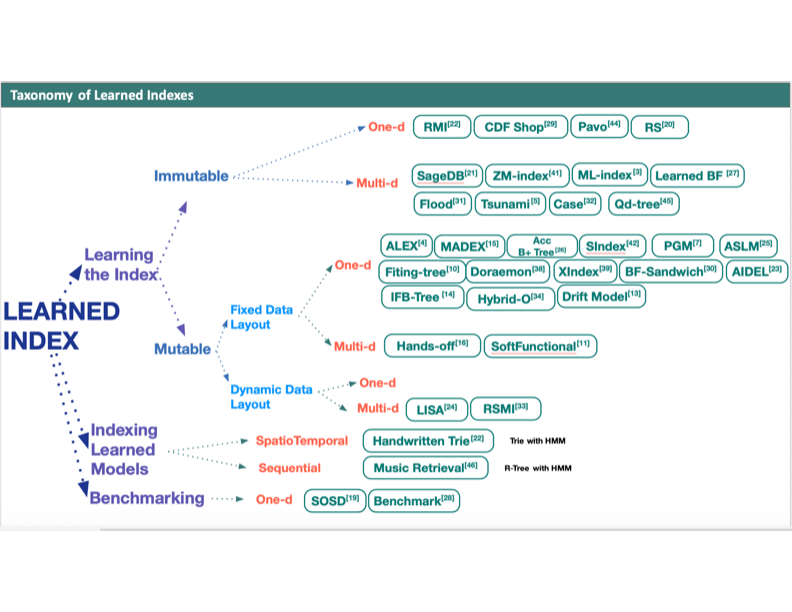
In the taxonomy, we distinguish
between two main approaches:
- Indexing the
Learned Models vs.
- Learning the Index
By indexing
the learned models, we refer to the following problem. Assume that
we are given a collection of learned models, where each model represents (and helps
recognize) a certain object class, e.g., a learned model that represents the
class dog, another that represents that class cat, etc. Given a query object, one
needs to execute each of the models to identify that model that produces the
highest matching score for the given query object. The question is:
Can we index the learned models to speed up the matching
process?
Several indexes have been
proposed that index these learned models to speed up the matching process
(e.g., see [1,46]).
In contrast, by learning the index, we refer to the problem of
substituting a traditional database index, e.g., a B+-tree, by a machine-learning
based model. Instead of searching the B+-tree to locate the leaf
page that contains an input search key, one uses an ML model that predicts the
location (or the leaf page) that contains the search key [22].
In the tutorial, we give example
indexes that follow each of the two approaches.
In the taxonomy, we further
distinguish between learned indexes along the following dimension:
- Learned indexes that support static data sets vs.
- Learned indexes that support updates
Notice that the issue of
supporting static vs. dynamic data sets is crucial due to the fact that
learning an index needs offline training that is relatively slow in nature.
Thus, learned indexes that support updates need to accommodate for this fact
and still support online response.
Next, we distinguish between learned
indexes along the dimensionality of the data.
- Learned indexes for
one-dimensional data vs.
- Learned indexes for
multi-dimensional data
Finally, we close by discussing open research
problems.
Here are the slides and video for
the SIGSPATIAL 2020 tutorial: <slides>
and <video>
Extended Version of the slides
(V2.0): <slides>
In this version, in addition to covering
more learned multi-dimensional indexes, we extend the taxonomy to cover the
following new dimension:
- Learned indexes with
fixed data layout vs.
- Learned indexes with
dynamic data layout
PRESENTERS
 Abdullah Al Mamun
Abdullah Al Mamun
Abdullah is a PhD student at the
Department of Computer Science (CS), Purdue University. His research interests
are in the area of Learned Index Structures, particularly, in the area of
Learned Multidimensional and Spatial Indexes. Previously, he completed his MS
in CS from Memorial University of Newfoundland, Canada.
 Hao Wu
Hao Wu
Hao is a senior undergraduate student
at Purdue University with majors in Data Science, Statistics-Math, Aviation
Management. He is interested in ML-oriented research as well as its application
in data-driven multi-disciplinary projects.
 Walid G. Aref
Walid G. Aref
Walid is a professor of computer
science at Purdue. His research interests are in extending the functionality of
database systems in support of emerging applications, e.g., spatial, spatio-temporal, graph, biological, and sensor databases.
His focus is on query processing, indexing, data streaming, and geographic
information systems (GIS). Walid’s research has been supported by the National
Science Foundation, the National Institute of Health, Purdue Research
Foundation, CERIAS, Panasonic, and Microsoft Corp. In 2001, he received the
CAREER Award from the National Science Foundation and in 2004, he received a
Purdue University Faculty Scholar award. Walid is a member of Purdue’s CERIAS.
He is the Editor-in-Chief of the ACM Transactions of Spatial Algorithms and
Systems (ACM TSAS), an editorial board member of the Journal of Spatial
Information Science (JOSIS), and has served as an editor of the VLDB Journal
and the ACM Transactions of Database Systems (ACM TODS). Walid has won several
best paper awards including the 2016 VLDB ten-year best paper award. He is a
Fellow of the IEEE, and a member of the ACM. Between 2011 and 2014, Walid has
served as the chair of the ACM Special Interest Groupon Spatial Information
(SIGSPATIAL).
REFERENCES
[1] Walid Aref,
Daniel Barbará, and Padmavathi Vallabhaneni.
1995. The Handwritten Trie: Indexing Electronic Ink.
SIGMOD Rec.24, 2 (May 1995), 151–162. https://doi.org/10.1145/568271.223811
[2] Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger.1990. The
R*-tree: an efficient and robust access method for points and rectangles. In
Proceedings of the 1990 ACM SIGMOD international conference on Management of
data. 322–331.
[3] Angjela
Davitkova, Evica Milchevski, and Sebastian Michel. 2020. The ML-Index: A
Multidimensional, Learned Index for Point, Range, and Nearest-Neighbor Queries.. In EDBT. 407–410.
[4] Jialin
Ding, Umar Farooq Minhas, Hantian Zhang, Yinan Li,
Chi Wang, Badrish Chandramouli,
Johannes Gehrke, Donald Kossmann,
and David Lomet. 2019. ALEX: An Updatable Adaptive
Learned Index. arXiv preprint arXiv:1905.08898(2019).
[5] Jialin Ding,
Vikram Nathan, Mohammad Alizadeh, and Tim Kraska. 2020. Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads. arXiv preprint arXiv:2006.13282(2020).
[6] Paolo Ferragina
and Giorgio Vinciguerra. 2020. Learned Data
Structures. In Recent Trends in Learning From
Data, Luca Oneto, Nicolò
Navarin, AlessandroSperduti, and Davide Anguita (Eds.). Springer International Publishing, 5-41.
https://doi.org/10.1007/978-3-030-43883-8_2
[7] Paolo Ferragina
and Giorgio Vinciguerra. 2020. The PGM-index.
Proceedings of the VLDB Endowment13, 8 (Apr 2020), 1162–1175. https://doi.org/10.14778/3389133.3389135
[8] Paolo Ferragina,
Giorgio Vinciguerra, and Michele Miccinesi.
2019. Superseding traditional indexes by orchestrating learning and
geometry. arXiv preprintarXiv:1903.00507(2019).
[9] Raphael A. Finkel and Jon
Louis Bentley. 1974. Quad trees a data structure for retrieval on composite
keys. Acta informatica4, 1 (1974), 1–9.
[10] Alex Galakatos,
Michael Markovitch, Carsten Binnig, Rodrigo Fonseca,
and Tim Kraska. 2019. Fiting-tree:
A data-aware index structure. In Proceedings of the 2019International
Conference on Management of Data. 1189–1206.
[11] Behzad Ghaffari,
Ali Hadian, and Thomas Heinis.
2020. Leveraging Soft Functional Dependencies
for Indexing Multi-dimensional Data. arXiv
preprintarXiv:2006.16393(2020).
[12] Antonin Guttman. 1984.
R-trees: A dynamic index structure for spatial searching. In Proceedings of the
1984 ACM SIGMOD international conference on Management of data. 47–57.
[13] Ali Hadian
and Thomas Heinis. 2019. Considerations for
handling updates in learned index structures. In Proceedings of the Second
International Workshop on Exploiting Artificial Intelligence Techniques for
Data Management. ACM, 3.
[14] Ali Hadian
and Thomas Heinis. 2019. Interpolation-friendly
B-trees: Bridging the gap between algorithmic and learned indexes. In22nd
International Conference on Extending Database Technology (EDBT 2019). https://doi.org/10.5441/002/edbt.2019.93
[15] Ali Hadian
and Thomas Heinis. 2020. MADEX: Learning-augmented
Algorithmic Index Structures. In Proceedings of the 2nd International Workshop
on Applied AI for Database Systems and Applications.
[16] Ali Hadian,
Ankit Kumar, and Thomas Heinis. 2020. Hands-off Model
Integration in Spatial Index Structures. In Proceedings of the 2nd
International Workshop on Applied AI for Database Systems and Applications.
[17] Benjamin Hilprecht,
Andreas Schmidt, Moritz Kulessa, Alejandro Molina,
Kristian Kersting, and Carsten Binnig. 2020. DeepDB: Learn from Data, Not from Queries!13, 7 (2020).
[18] Stratos Idreos
and Tim Kraska. 2019. From Auto-tuning One Size
Fits All to Self-designed and Learned Data-intensive Systems (Tutorial). In
Proceedings of the 2019 International Conference on Management of Data, SIGMOD
Conference2019, Amsterdam, The Netherlands, June 30 - July 5, 2019. 2054–2059.
http://people.csail.mit.edu/kraska/pub/sigmod19tutorialpart2.pdf
[19] Andreas Kipf,
Ryan Marcus, Alexander van Renen, Mihail
Stoian, Alfons Kemper,Tim
Kraska, and Thomas Neumann. 2019. SOSD: A
Benchmark for Learned Indexes. ArXivabs/1911.13014
(2019).
[20] Andreas Kipf,
Ryan Marcus, Alexander van Renen, Mihail
Stoian, Alfons Kemper,Tim
Kraska, and Thomas Neumann. 2020. RadixSpline:
A Single-Pass Learned Index.ArXivabs/2004.14541
(2020).
[21] Tim Kraska,
Mohammad Alizadeh, Alex Beutel, Ed H Chi, Jialin Ding, Ani Kristo,Guillaume
Leclerc, Samuel Madden, Hongzi Mao, and Vikram
Nathan. 2019.Sagedb: A learned database system. (2019).
[22] Tim Kraska,
Alex Beutel, Ed H Chi, Jeffrey Dean, and Neoklis Polyzotis. 2018.The case
for learned index structures. In Proceedings of the 2018 International
Conference on Management of Data. ACM, 489–504.
[23] Pengfei
Li, Yu Hua, Pengfei Zuo,
and Jingnan Jia. 2019. A Scalable Learned
Index Scheme in Storage Systems. CoRRabs/1905.06256
(2019). arXiv:1905.06256http://arxiv.org/abs/1905.06256
[24] Pengfei
Li, Hua Lu, Qian Zheng, Long Yang, and Gang Pan. 2020. LISA: A Learned Index
Structure for Spatial Data. SIGMOD(2020)
[25] Xin Li, Jingdong
Li, and Xiaoling Wang. 2019. ASLM: Adaptive single
layer model for learned index. In International Conference on Database Systems
for Advanced Applications. Springer, 80–95.
[26] A Llavesh,
Utku Sirin, R West, and A Ailamaki. 2019. Accelerating b+ tree search by using simple
machine learning techniques. In Proceedings of the 1stInternational Workshop on
Applied AI for Database Systems and Applications.
[27] Stephen Macke, Alex Beutel, Tim Kraska, Maheswaran Sathiamoorthy,Derek Zhiyuan Cheng, and EH Chi. 2018. Lifting the curse of
multidimensional data with learned existence indexes. InWorkshop
on ML for Systems at NeurIPS.
[28] Ryan Marcus, Andreas Kipf, Alexander van Renen, Mihail Stoian, Sanchit Misra,Alfons Kemper, Thomas
Neumann, and Tim Kraska. 2020. Benchmarking Learned
Indexes. arXiv preprint arXiv:2006.12804(2020).
[29] Ryan Marcus, Emily Zhang,
and Tim Kraska. 2020. CDFShop:
Exploring and Optimizing Learned Index Structures. In Proceedings of the 2020
ACM SIGMOD International Conference on Management of Data. 2789–2792.
[30] Michael Mitzenmacher.
2018. A model for learned bloom filters and optimizing by sandwiching. In
Advances in Neural Information Processing Systems. 464–473.
[31] Vikram Nathan, Jialin Ding, Mohammad Alizadeh, and Tim Kraska.
2020. Learning Multi-dimensional Indexes. In Proceedings of the 2020 ACM SIGMOD
International Conference on Management of Data. 985–1000.
[32] Varun Pandey, Alexander van Renen, Andreas Kipf, Ibrahim Sabek, Jialin Ding,and Alfons Kemper.
2020. The Case for Learned Spatial Indexes. arXiv
preprintarXiv:2008.10349(2020).
[33] Jianzhong Qi, Guanli Liu, Christian S Jensen, and Lars Kulik. 2020.
Effectively learning spatial indices. Proceedings of the VLDB Endowment13, 12
(2020), 2341–2354.
[34] Wenwen
Qu, Xiaoling Wang, Jingdong
Li, and Xin Li. 2019. Hybrid indexes by exploring traditional B-tree and linear
regression. In International Conference on Web Information Systems and
Applications. Springer, 601–613.
[35] Ibrahim Sabek
and Mohamed F Mokbel. 2020. Machine learning meets big
spatial data. In2020 IEEE 36th International Conference on Data Engineering
(ICDE). IEEE,1782–1785.
[36] Hanan Samet.
1984. The quadtree and related hierarchical data structures. ACM Computing
Surveys (CSUR)16, 2 (1984), 187–260.
[37] Hanan Samet.
2006.Foundations of multidimensional and metric data structures. Morgan
Kaufmann.
[38] Chuzhe
Tang, Zhiyuan Dong, Minjie
Wang, Zhaoguo Wang, and Haibo
Chen.2019. Learned Indexes for Dynamic Workloads. arXiv
preprint arXiv:1902.00655(2019).
[39] Chuzhe Tang, Youyun Wang, Zhiyuan Dong, Gansen Hu, Zhaoguo Wang, MinjieWang, and Haibo Chen. 2020. XIndex: a
scalable learned index for multicore data storage. Proceedings of the 25th ACM
SIGPLAN Symposium on Principles andPractice of
Parallel Programming(2020).
[40] Peter
Van Sandt, Yannis Chronis, and Jignesh M Patel. 2019.
Efficiently Searching In-Memory Sorted Arrays: Revenge of the Interpolation Search?. In Proceedingsof the 2019
International Conference on Management of Data. ACM, 36–53.
[41] Haixin Wang, Xiaoyi Fu, Jianliang Xu, and Hua Lu. 2019. Learned Index for Spatial
Queries. In2019 20th IEEE International Conference on Mobile Data Management(MDM). IEEE, 569–574.
[42] Youyun Wang, Chuzhe Tang, Zhaoguo Wang, and Haibo Chen.
2020. SIndex: a scalable learned index for string
keys. In Proceedings of the 11th ACM SIGOPSAsia-Pacific
Workshop on Systems. 17–24.
[43] Yingjun Wu, Jia Yu, Yuanyuan Tian, Richard Sidle, and
Ronald Barber. 2019.Designing Succinct Secondary Indexing Mechanism by
Exploiting Column Correlations. arXiv preprint
arXiv:1903.11203(2019).
[44] Wenkun Xiang, Hao Zhang, Rui Cui, Xing Chu, Keqin Li, and Wei Zhou. 2018.Pavo: A RNN-Based Learned
Inverted Index, Supervised or Unsupervised?IEEEAccess7
(2018), 293–303.
[45] Zongheng Yang, Badrish Chandramouli, Chi Wang, Johannes Gehrke,
Yinan Li,Umar Farooq Minhas,
Per-Åke Larson, Donald Kossmann,
and Rajeev Acharya.2020. Qd-tree: Learning Data
Layouts for Big Data Analytics. In Proceedings of the2020 ACM SIGMOD
International Conference on Management of Data. 193–208.
[46] Jin, Hui, and H. V. Jagadish. "Indexing Hidden Markov
Models for Music Retrieval." In ISMIR. 2002.
[47] Babu, G.
Phanendra. "Self-organizing neural networks for
spatial data." Pattern Recognition Letters 18, no. 2 (1997): 133-142.
[48] J. Qi,
Y. Tao, Y. Chang, and R. Zhang. Theoretically optimal and empirically efficient
R-trees with strong parallelizability. PVLDB, 11(5):621–634, 2018.