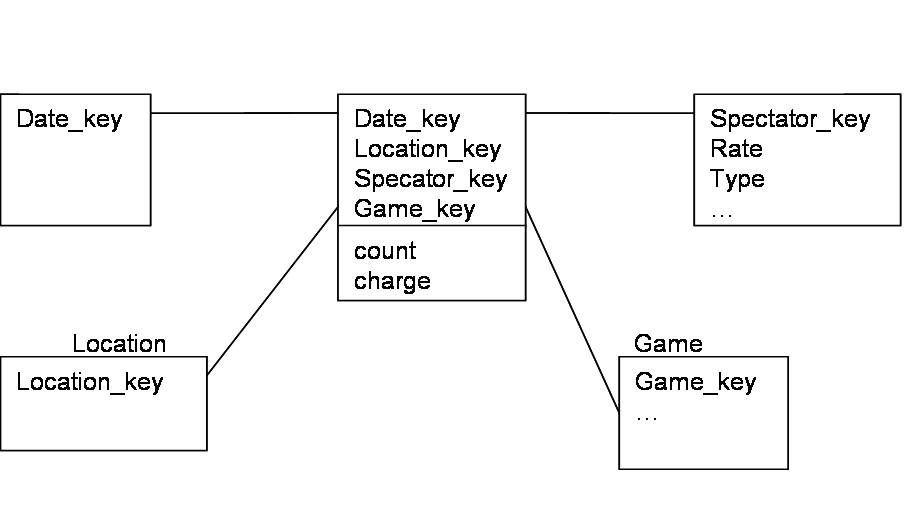
 (1 point)
(1 point)
b) slice/dice on spectator.type=student and location=GM_Place, year=2000; then Roll-up to remove game, date. (1 point)
b) One approach would be to identify values that differed significantly from their bin mean. One problem is that an item may be far from its bin mean, but closer to the mean of another bin (e.g., 46) - so distance from closest bin would make more sense. "Significant" is a challenge, though - an age of 7 would certainly seem an outlier in this data, but 46 doesn't seem to be - yet both are 6 from the nearest bin. (0.25 point)
3.5 a) norm(x) = x-13/(70-13): 0.39
b) norm(x) = (x-avg) / sdev = (35 - 30) / 13 = 0.38
c) norm(x) = x/100 = .35
d) My preference would be decimal scaling, as it preserves concepts of minimum and maximum age and relative distance. However, this would fail if anyone in the data set were over 100, since all ages would now be far from the maximum normalized value.
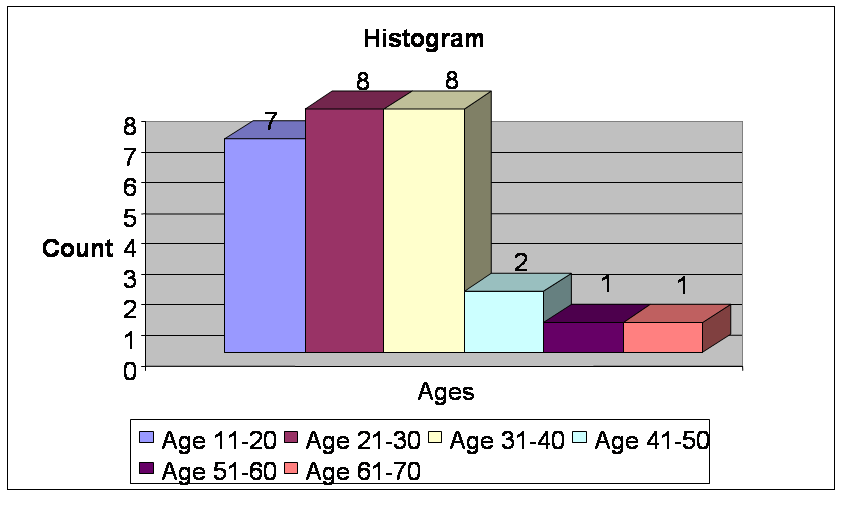 (1 point)
(1 point)